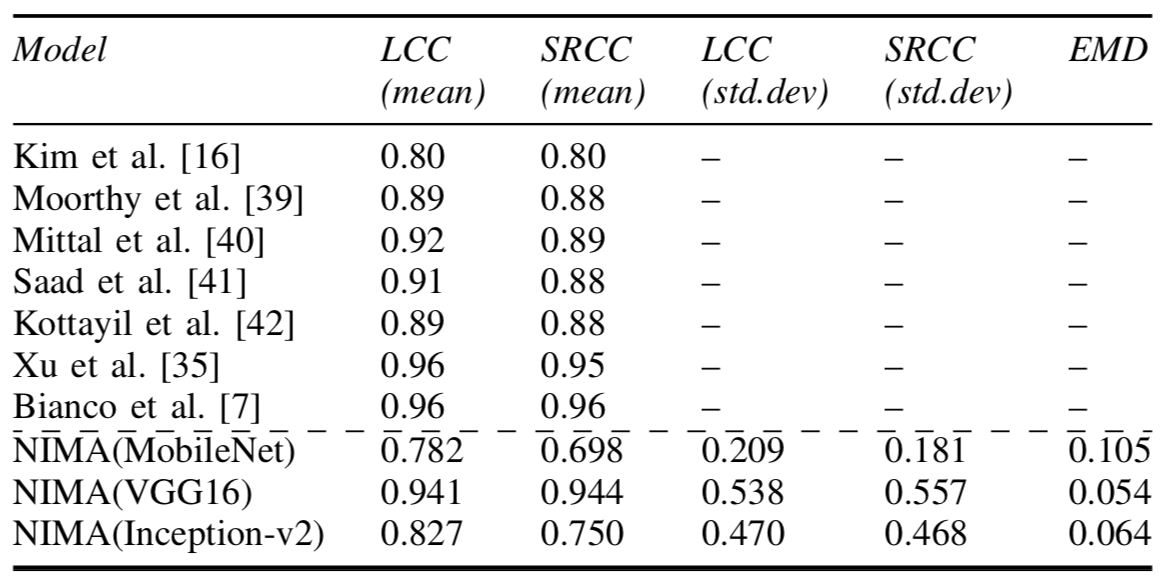
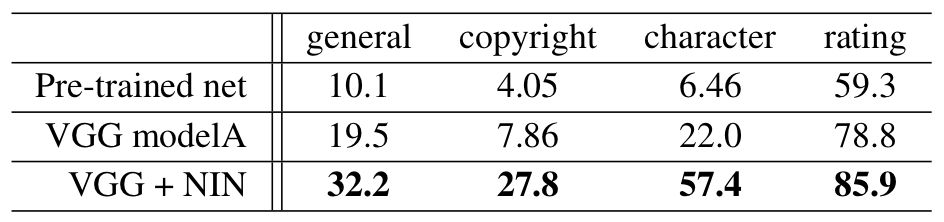
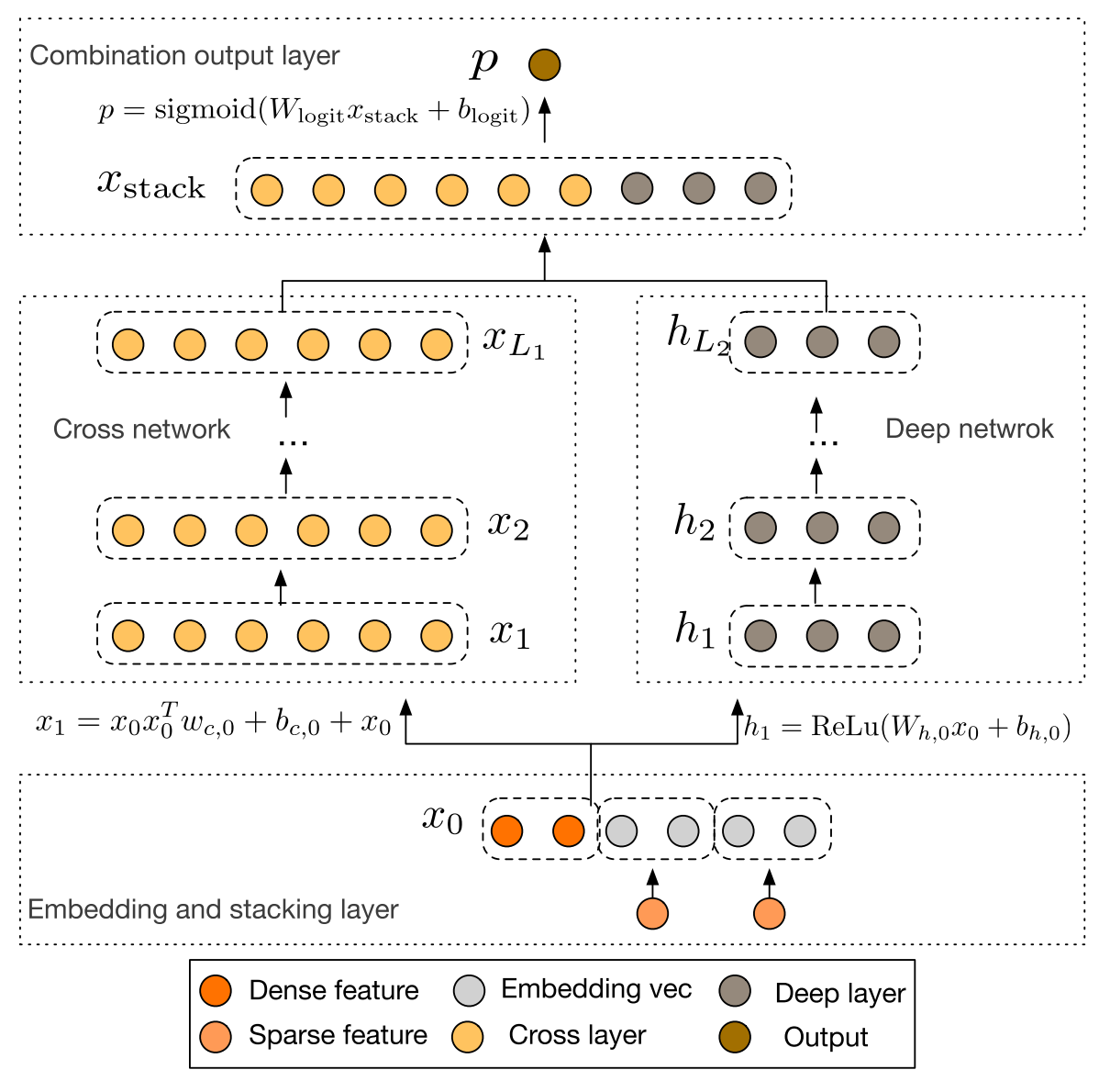
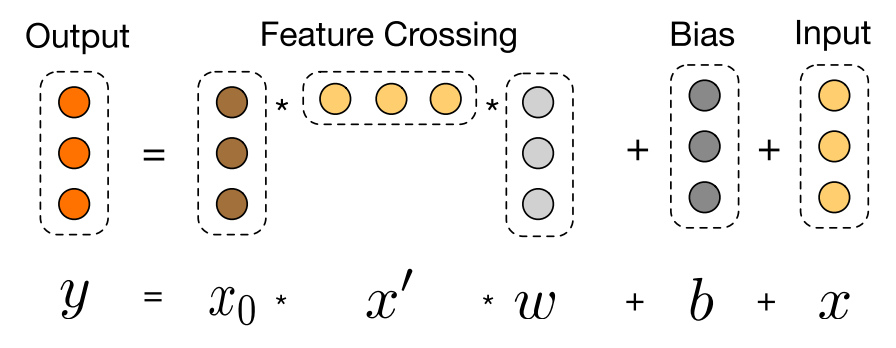
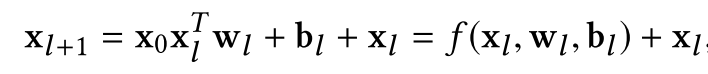在常规的基于深度学习的点击率预估模型中, 用户的兴趣通常是用固定的向量来表示的, 无法候选的商品是什么, 用户的兴趣向量都是相同的。 这并不是合理的, 对于某一个商品来说, 决定用户点还是不点, 只与用户的历史行为中的一部分有关系。 很自然地, 我们想到使用Attention的方法来对不同的历史兴趣进行软选择。这就是阿里Deep Interest Network的做法。
论文的主要工作便是在用户兴趣的表征上使用了Attention机制(论文中称之为local activation unit), 不过稍微有一点不一样。 在标准的Attention中, 权重是通过softmax进行了规一化的, 在DIN中取消了归一化。 不过没看到这个的效果和直接使用Attention的区别。
论文同时提出了针对模型训练的两点改进:
- 基于Mini-Batch的L2正则化。 常规的正则化下, 每次迭代都涉及到对所有参数的更新,对于亿级的稀疏特征来说, 这个代价太大了。 论文中将正则化涉及的参数限制在了仅在Mini-batch出现过的特征所影响的权重, 有效地缓解了过拟合的问题。
- 一种新的,针对数据分布自适应的激活函数,称为Dice。
参考
- 深度兴趣网络(DIN) · alibaba/x-deeplearning Wiki · GitHub)
- Deep Models — deepCTR 1.0.1 documentation
- 论文地址: [arXiv‘2017]Zhou, Guorui, et al.Deep interest network for click-through rate prediction, arXiv preprint arXiv:1706.06978 (2017).